Our Approach
Our goal is to provide a means by which members of a non-expert community can pose, view, and share their photos inside a 3D world model such as Google Earth.
Critical to our mission is the desire to include any and all photos, with no technical or editorial biases for some types of imagery over others. If someone wants to pose a square meter of pavement that could have been shot anywhere, or a close-up of a finger pointing, or graffiti, these images should be included. We believe that creativity should drive technology, not the other way around.
Our approach is also unorthodox from the traditional perspective of the computer science and engineering communities in that we are assuming that people will be willing to help out a little, particularly if it is fast, easy, and fun. We’re specifying that it should be possible for photographs to be aligned in under one minute by a 10-year-old, and as such, participation in the project will be easy and enjoyable as well as productive.
We fully expect cameras of the future to have the sensing and intelligence to fully automate this process. But we’re not there yet. “Viewfinder” is intended to be a getting-from-here-to-there strategy; it is an artistic intervention as well as a technological innovation.
Pose-Finding: Two Solutions
We are developing two browser-based, pose-finding solutions based on our approach: a 2D-to-2D solution and a 2D-to-3D solution. Both begin with the same first step.
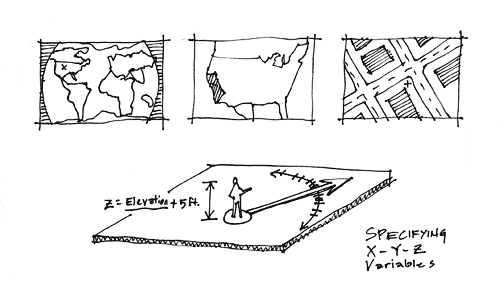
Figure 2. Specifying x, y, and z variables.
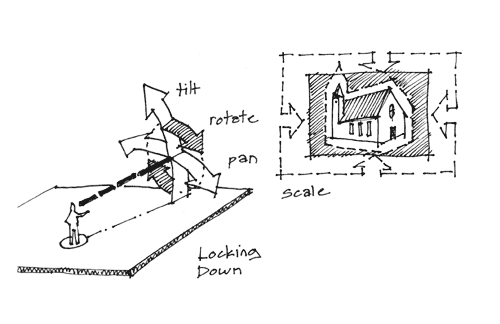
Figure 3. Locking down x, y, and z variables.
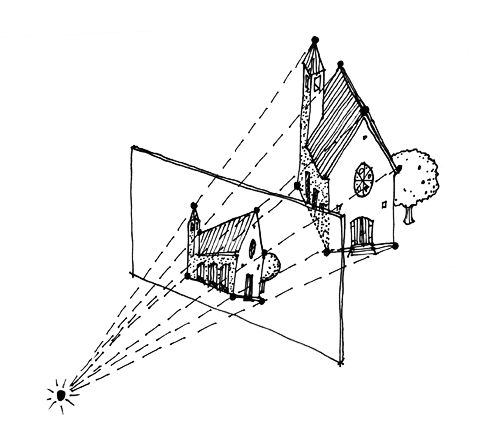
Figure 4. Point correspondences between 2D photo and 3D model.
The first step is for a human helper to upload a photo and mark a corresponding spot on a zoomed-in interactive map of the world. Anecdotal evidence shows that people can usually remember such locations to within a meter or less if they can see a map and aerial photo with sufficient resolution. GPS data can also be used. The helper also indicates the general direction that the camera was aimed. Next to the map a screen grab appears of the indicated location from a 3D world model, taken from the eye level of an average adult. The screen grab approximates the same composition as the photo.
For the 2D-to-2D solution, this position is taken as fixed. With the x, y, and z variables now locked down, the search problem is reduced to panning, tilting, rotating, and (assuming a known aspect ratio) scaling the image to match the view in Google Earth – four variables, and an easy problem for humans to solve. One solution is to match a single correspondence point, then scale and rotate the overlaid photo to align everything else. Another way is to simply match two points. For this solution, the screen grab from a 3D world model can be simply a 2D image.
For the 2D-to-3D solution, the screen grab from a 3D world model is a 2D image but contains depth or “z” data for every 2D pixel. The starting position is taken as an approximation. The human helper matches corresponding points between the photo and the screen grab and all pose variables lock down to a “best fit” solution.
One advantage of the 2D-to-2D solution is that the required computation, as well as the task requested of the human helper, are both relatively simple. Another advantage is that no additional data is required from the 3D world model beyond a standard 2D screen grab. The disadvantage is that, if the starting positions are incorrect, a good pose cannot be found, and the helper has to return to the first step. This is particularly true if the height at which the photo was taken was different from just above ground level. A height adjustment control for this first step would be helpful, but would add complexity.
The advantage of the 2D-to-3D solution is that all variables can find their best fit as corresponding points are matched; in the end this is the more robust solution. The disadvantage is that the computation is fundamentally more complex, particularly since corresponding points have more value if they are non-coplanar with each other. A more practical disadvantage is that the z-data from the 3D model must be available, and this is currently not true for either Google Earth or Microsoft Live.
Viewing Posed Photos
Once a photo’s pose is known, it can be properly placed in the 3D model. One universal aspect is that a posed photo viewed from the nodal point – the origin point of the camera – will always appear perfectly aligned with respect to the 3D model. From any other point, different areas of the photo may or may not appear aligned, in part depending on the content of the imagery, but overall alignment will be problematic at best.
One school of thought is to show only posed photos from the nodal point and to feature graphic “indicators” for the photos, such as empty frames and frustums, the pyramid-like radiating lines of the photos’ field of view, connecting the camera position to each corner of the resulting image. Another approach is to fade up posed photos as the viewer’s point of view nears the camera’s nodal point, so that any misalignment artifacts appear only fleetingly. A third school of thought favors allowing the photo to be fully visible at all times, regardless of the viewer’s position. A related feature is a “snap-to” function as the viewer approaches a nodal point. These features (when and how the posed photo becomes visible, the use of graphical indicators and snap-to functions) each have an impact on the overall user experience.
Another factor is the question of where to place the posed photo within the 3D model. In theory, the photo can be placed anywhere along the frustum lines and will appear perfectly aligned when viewed from the nodal point: it can be near and small or far and big, or anywhere in between. In practice, if the photo is too near and small, it will be difficult to find (perhaps requiring assistance in the form of snapping); if it’s too far and big, the photo will begin to cut through objects inside the 3D model such as buildings.